llama 3.2-j9九游会登录
方案概览
本方案介绍了在modelarts lite server上使用昇腾计算资源ascend snt9b开展llama 3.2-vision-11b模型的训练过程,包括finetune full训练和lora训练。
约束限制
- 本方案目前仅适用于企业客户。
- 本文档适配昇腾云modelarts 6.3.912版本,请参考获取配套版本的软件包和镜像,请严格遵照版本配套关系使用本文档。
- 本文档中的模型运行环境是modelarts lite server。
- 镜像适配的cann版本是cann_8.0.rc3。
- 驱动版本:23.0.6。
- pytorch版本:2.1.0。
- 确保容器可以访问公网。
资源规格要求
推荐使用“西南-贵阳一”region上的server资源和ascend snt9b。
获取软件和镜像
|
分类 |
名称 |
获取路径 |
|---|---|---|
|
插件代码包 |
ascendcloud-6.3.912软件包中的ascendcloud-aigc-6.3.912-xxx.zip 文件名中的xxx表示具体的时间戳,以包名发布的实际时间为准。 |
获取路径:,在此路径中查找下载modelarts 6.3.912 版本。
说明:
如果上述软件获取路径打开后未显示相应的软件信息,说明您没有下载权限,请联系您所在企业的华为方j9九游会登录的技术支持下载获取。 |
|
基础镜像包 |
swr.cn-southwest-2.myhuaweicloud.com/atelier/pytorch_2_1_ascend:pytorch_2.1.0-cann_8.0.rc3-py_3.9-hce_2.0.2409-aarch64-snt9b-20241213131522-aafe527 |
swr上拉取。 |
步骤一:检查环境
- 请参考,购买server资源,并确保机器已开通,密码已获取,能通过ssh登录,不同机器之间网络互通。

购买server资源时如果无可选资源规格,需要联系华为云j9九游会登录的技术支持申请开通。
当容器需要提供服务给多个用户,或者多个用户共享使用该容器时,应限制容器访问openstack的管理地址(169.254.169.254),以防止容器获取宿主机的元数据。具体操作请参见。
- ssh登录机器后,检查npu卡状态。运行如下命令,返回npu设备信息。
npu-smi info # 在每个实例节点上运行此命令可以看到npu卡状态 npu-smi info -l | grep total # 在每个实例节点上运行此命令可以看到总卡数
如出现错误,可能是机器上的npu设备没有正常安装,或者npu镜像被其他容器挂载。请先正常安装固件和驱动,或释放被挂载的npu。
- 检查是否安装docker。
docker -v #检查docker是否安装
如尚未安装,运行以下命令安装docker。
yum install -y docker-engine.aarch64 docker-engine-selinux.noarch docker-runc.aarch64
- 配置ip转发,用于容器内的网络访问。执行以下命令查看net.ipv4.ip_forward配置项的值,如果为1,可跳过此步骤。
sysctl -p | grep net.ipv4.ip_forward
如果net.ipv4.ip_forward配置项的值不为1,执行以下命令配置ip转发。sed -i 's/net\.ipv4\.ip_forward=0/net\.ipv4\.ip_forward=1/g' /etc/sysctl.conf sysctl -p | grep net.ipv4.ip_forward
步骤二:获取基础镜像
建议使用官方提供的镜像部署推理服务。镜像地址{image_url}获取请参见表1。
docker pull {image_url}
步骤三:启动容器镜像
启动容器镜像,启动前可以根据实际需要增加修改参数。
docker run -itd --net=host \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
--shm-size=1024g \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/ascend/driver:/usr/local/ascend/driver \
-v /var/log/npu/:/usr/slog \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v ${work_dir}:${container_work_dir} \
--name ${container_name} \
${image_id} \
/bin/bash
- --device=/dev/davincix:挂载npu设备,示例中挂载了8张卡
- work_dir:工作目录,目录下存放着训练所需代码、数据等文件
- container_work_dir:容器工作目录,一般同work_dir
- container_name:自定义容器名
- image_id:镜像id,通过docker images来查看拉取的镜像id。
步骤四:进入容器
通过容器名称进入容器中。默认使用ma-user用户执行后续命令。
docker exec -it ${container_name} bash
修改权限。
sudo chown -r ma-user:ma-group ${container_work_dir}
此步骤可能需要密码或root权限。
步骤五:下载代码安装环境
下载华为侧插件代码包ascendcloud-aigc-6.3.912-xxx.zip文件,获取路径参见表1 获取软件和镜像。
mv ascendcloud-aigc-6.3.912-*.zip ${container_work_dir}
cd ${container_work_dir}
unzip ascendcloud-aigc-6.3.912-*.zip
cp -r multimodal_algorithm/llama32_vision/train/6b33108084eb4a8efd5d09090a3e1a51f6920129/* ${container_work_dir}
# 下载复制后${container_work_dir}目录下存在如下5个文件
# 1.llama32_vision_install.sh
# 2.custom_dataset_info_demo.json
# 3.llama32_vision.patch
# 4.llama32_vision_11b_finetune_sft.sh
# 5.llama32_vision_11b_finetune_lora.sh
安装代码&环境
bash llama32_vision_install.sh
步骤六:增加适配代码
# 安装优化加速包
cd ${container_work_dir}/multimodal_algorithm/ascendcloud_multimodal_plugin
pip install -e .
# 使能优化加速包(此步默认在环境安装阶段已完成,可忽略)
# 在${container_work_dir}/ms-swift/swift/cli/sft.py中引入优化代码包 from ascendcloud_multimodal.train.models.llama32_vision import ascend_modeling_mllama
步骤七:数据集下载与制作
下载coco2014数据集:,。本节展示了基于coco2014数据集制作一个演示的demo数据集,若用户有自定义数据集需求,可按以下叙述的数据集格式构建用户自定义数据集。
在${container_work_dir}目录下载以上数据集,并将其放置在${container_work_dir}路径下;
cd ${container_work_dir}
wget http://images.cocodataset.org/zips/train2014.zip && unzip train2014.zip
wget https://github.com/opengvlab/internvl/releases/download/data/coco_karpathy_train_567k.zip && unzip coco_karpathy_train_567k.zip
下载coco2014数据集后目录结构如下:
${container_work_dir}
├── train2014
│ ├── coco_train2014_000000270070.jpg
│ ├── coco_train2014_000000101772.jpg
│ ├── coco_train2014_000000359320.jpg
│ ...
│ ├── coco_train2014_000000177349.jpg
│ ├── coco_train2014_000000283267.jpg
│ └── coco_train2014_000000334463.jpg
└── coco_karpathy_train_567k.jsonl
对于coco_karpathy_train_567k.jsonl文件进行过滤,过滤出train2014目录下图片对应的数据,并按如下格式重新构建json文件(coco2014_train.json):
[
{
"id": "0",
"image": "train2014/coco_train2014_000000057870.jpg",
"conversations": [
{
"role": "user",
"content": "\nprovide a one-sentence caption for the provided image."
},
{
"role": "assistant",
"content": "a restaurant has modern wooden tables and chairs."
}
]
},
{
"id": "1",
"image": "train2014/coco_train2014_000000057870.jpg",
"conversations": [
{
"role": "user",
"content": "\nprovide a one-sentence caption for the provided image."
},
{
"role": "assistant",
"content": "a long restaurant table with rattan rounded back chairs."
}
]
},
...
...
...
{
"id": "413961",
"image": "train2014/coco_train2014_000000475546.jpg",
"conversations": [
{
"role": "user",
"content": "\nprovide a one-sentence caption for the provided image."
},
{
"role": "assistant",
"content": "group of people drinking wine at a public location."
}
]
},
{
"id": "413962",
"image": "train2014/coco_train2014_000000475546.jpg",
"conversations": [
{
"role": "user",
"content": "\nprovide a one-sentence caption for the provided image."
},
{
"role": "assistant",
"content": "three women and a man are sitting at a bar"
}
]
}
]
- 由于coco2014_train.json数据量过大,为方便适配,本指导中使用的是:取coco2014_train.json文件前4万条数据作为后续使用的demo数据集(命名为:coco2014_train_filter_40k.json);
- 启动训练脚本前,需检查并保证下载的数据集train2014文件夹与训练脚本均在工作目录${container_work_dir}下。
demo数据集配置指导如下:
修改custom_dataset_info_demo.json文件中dataset_path(${container_work_dir}/ms-swift/swift/llm/data目录下)参数为以上步骤制作的json文件(coco2014_train_filter_40k.json)的路径;custom_dataset_info_demo.json文件如下。
{
"coco2014_train_40k_demo": {
"dataset_path": "path/to/coco2014_train_filter_40k.json",
"image": "image",
"conversations": {
"user_role": "user",
"assistant_role": "assistant",
"from_key": "role",
"value_key": "content",
"error_strategy": "delete",
"media_type": "image",
"media_key": "image"
}
}
}
步骤八:下载模型权重
从modelscope下载或将您已下载的权重文件上传到容器能正常访问的目录。
方式1:手动下载,并将其放置在${container_work_dir}路径下。
方式2:利用git下载,须确保git lfs已成功安装:
cd ${container_work_dir}
git clone https://www.modelscope.cn/llm-research/llama-3.2-11b-vision-instruct.git
cd llama-3.2-11b-vision-instruct
git lfs pull
步骤九:开始训练
单机训练
cd ${container_work_dir}
# 指定model_path为步骤八:下载模型权重下载的llama-3.2-11b-vision-instruct权重路径
# 指定dataset参数为步骤七:数据集下载与制作中所述custom_dataset_info_demo.json中文件设置的数据集名称:coco2014_train_40k_demo
# 修改custom_dataset_info参数路径为${container_work_dir}/ms-swift/swift/llm/data/custom_dataset_info_demo.json
# finetune sft全参微调场景
model_path=path/to/llama-3.2-11b-vision-instruct \
dataset=coco2014_train_40k_demo \
custom_dataset_info=path/to/ms-swift/swift/llm/data/custom_dataset_info_demo.json \
work_dir=${container_work_dir} \
globol_batch_size=32 \
per_device_batch_size=2 \
bash llama32_vision_11b_finetune_sft.sh
# finetune lora微调场景
model_path=path/to/llama-3.2-11b-vision-instruct \
dataset=coco2014_train_40k_demo \
custom_dataset_info=path/to/ms-swift/swift/llm/data/custom_dataset_info_demo.json \
work_dir=${container_work_dir} \
globol_batch_size=32 \
per_device_batch_size=4 \
bash llama32_vision_11b_finetune_lora.sh
多机训练
cd ${container_work_dir}
# 指定model_path为步骤八:下载模型权重下载的llama-3.2-11b-vision-instruct权重路径
# 指定dataset参数为步骤七:数据集下载与制作中所述custom_dataset_info_demo.json中文件设置的数据集名称:coco2014_train_40k_demo
# 指定custom_dataset_info参数路径为${container_work_dir}/ms-swift/swift/llm/data/custom_dataset_info_demo.json
# finetune sft场景
model_path=path/to/llama-3.2-11b-vision-instruct \
dataset=coco2014_train_40k_demo \
custom_dataset_info=path/to/ms-swift/swift/llm/data/custom_dataset_info_demo.json \
work_dir=${container_work_dir} \
node_num=${node_num} \
node_rank=${node_rank} \
master_addr=${master_addr} \
globol_batch_size=32*${node_num} \
per_device_batch_size=2 \
bash llama32_vision_11b_finetune_sft.sh
# finetune lora场景
model_path=path/to/llama-3.2-11b-vision-instruct \
dataset=coco2014_train_40k_demo \
custom_dataset_info=path/to/ms-swift/swift/llm/data/custom_dataset_info_demo.json \
work_dir=${container_work_dir} \
node_num=${node_num} \
node_rank=${node_rank} \
master_addr=${master_addr} \
globol_batch_size=32*${node_num} \
per_device_batch_size=4 \
bash llama32_vision_11b_finetune_lora.sh
参数说明:
- node_num/node_num:机器数量,修改${node_num}为具体数字。
- node_rank/node_rank:机器rank num,主机为0,其余递增,修改${node_rank}为具体数字。
- master_addr/master_addr:主机ip地址,修改${master_addr}为主机ip。
- globol_batch_size:全局批次大小。
- per_device_batch_size:每张卡上的批次大小。
以单机结果为例,训练成功如下图所示。


附:loss曲线
loss结果
- sft全参微调npu训练结果loss收敛且趋势与gpu训练loss一致
图3 sft全参微调单机loss曲线对比结果
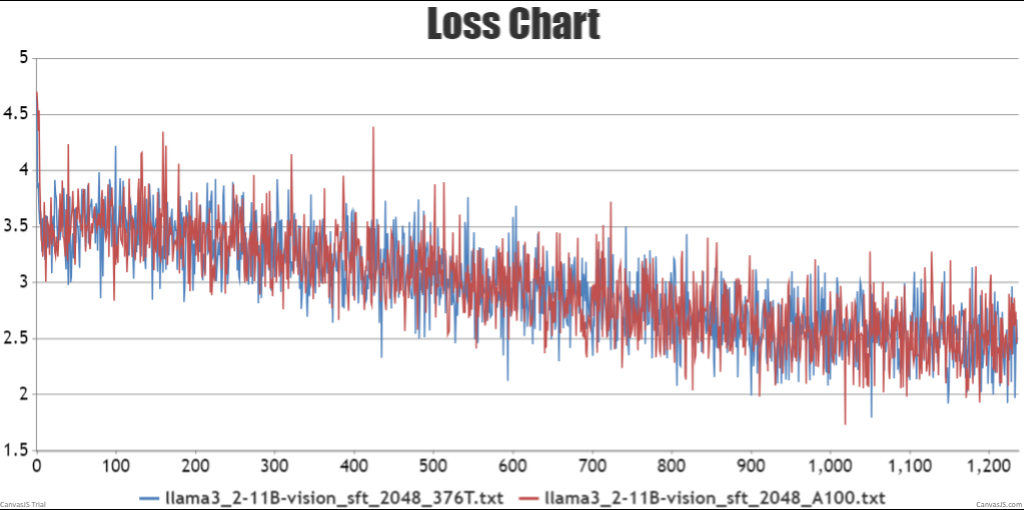 图4 sft全参微调双机loss曲线对比结果
图4 sft全参微调双机loss曲线对比结果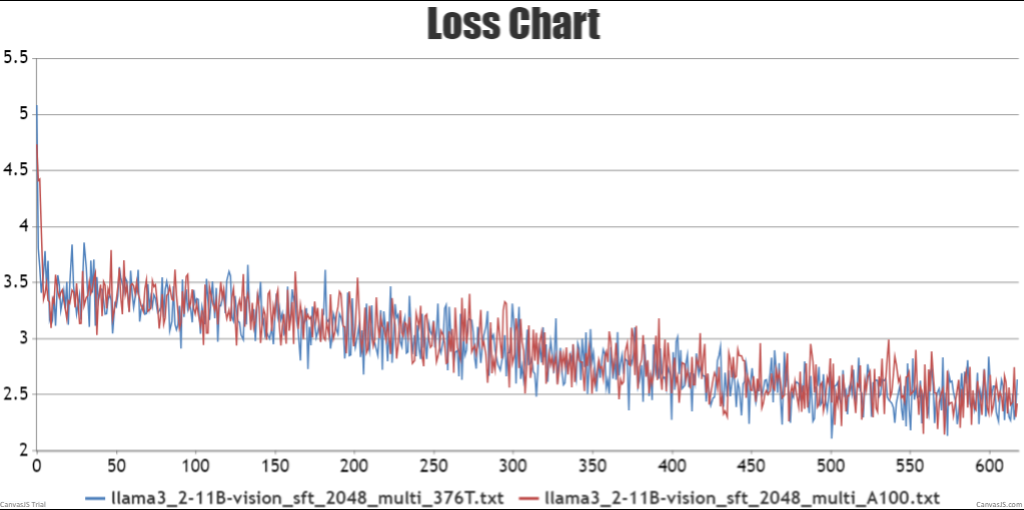
- lora微调npu训练结果loss收敛且趋势与gpu训练loss一致
图5 lora微调双机loss曲线对比结果
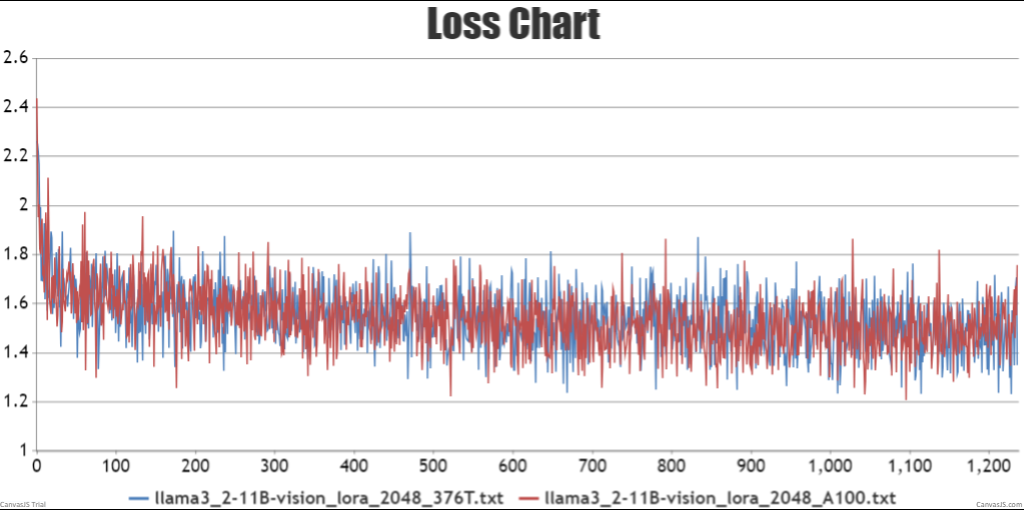 图6 lora微调双机loss曲线对比结果
图6 lora微调双机loss曲线对比结果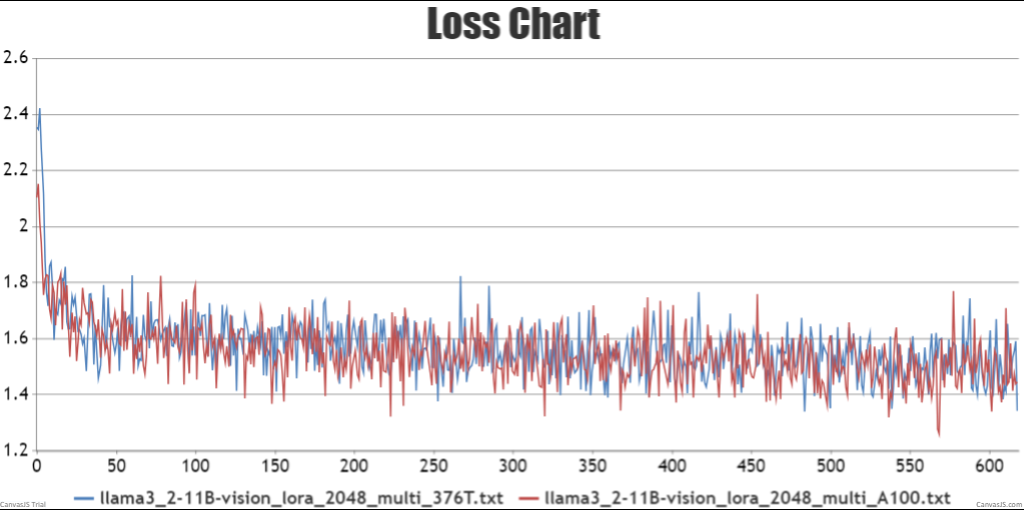
相关文档
意见反馈
文档内容是否对您有帮助?
如您有其它疑问,您也可以通过华为云社区问答频道来与我们联系探讨




